重庆13438161966

重庆13438161966







型号:Quadro RTX 4000
Turing GPU
2,304 NVIDIA ® CUDA ®核心
288 NVIDIA ® Tensor核心
36 NVIDIA ® RT核心
8GB GDDR6 记忆体
高达416GB/s 记忆体频宽
43T RTX-OPS
7.1 TFLOPS FP32 效能
Quadro RTX 4000将NVIDIA Turing GPU架构与最新的记忆体和显示技术相结合,以单插槽PCI-e结构提供最佳性能和功能。享受更大的流畅性与如照片真实感渲染,体验启用AI-应用更快的性能和创建详细的,栩栩如生的虚拟实境体验。更具成本效益和更加广泛与弹性的工作站机箱配置。

使用高达64X FSAA (SLI 模式下128倍) 大幅降低视觉混叠伪像或「锯齿」以获得优秀的影像品质和极为逼真的场景。
材质来自并成像到32K x 32K 表面以支援需要最高解析度和品质的影像处理应用程式。

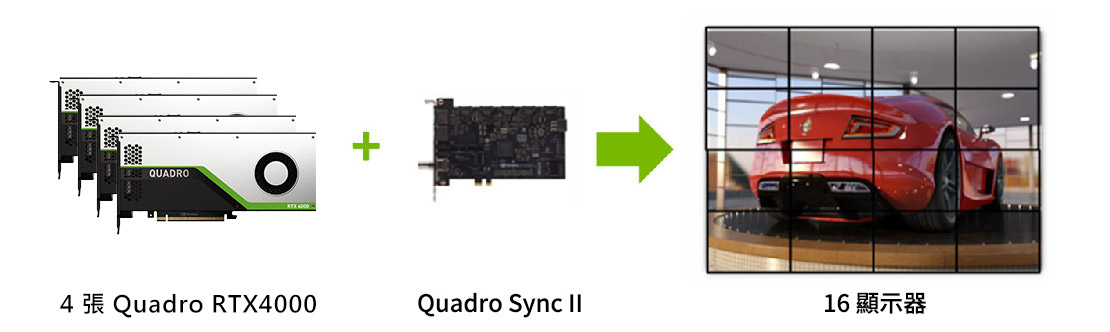
在单一系统的8 个GPU 中同步最多32 个显示器的显示和画面输出(透过两张Sync II 介面卡连接),减少建立高阶影像可视化环境所需的机器数量。
| CUDA 平行处理核心 | 2304 |
| NVIDIA Tensor 核心 | 288 |
| NVIDIA RT 核心 | 36 |
| 记忆体 | 8 GB GDDR6 |
| RTX-OPS | 43T |
| 光线投射 | 8 Giga Rays/Sec |
| 最高单精度(FP32) 效能 | 7.1 TFLOPS |
| 最高单精度(FP16) 效能 | 14.2 TFLOPS |
| 最高整数运算(INT8) 效能 | 28.5 TOPS |
| 深度学习TeraFLOPS 1 | 57.0 TFLOPS |
| 记忆体介面 | 256-bit |
| 记忆体频宽 | 最高416 GB/s |
| 最大功耗 | 160 W |
| 汇流排 | PCI Express 3.0 x 16 |
| 显示接头 | DP 1.4 (3) + VirtualLink (1) |
| 板型 | 4.4” 高x 9.5” 长 |
| 重量 | 479 g |
| 散热方案 | 主动式 |
| NVIDIA ® 3D Vision ®和3D Vision Pro | 由3 pin mini DIN 支援 |
| 框页锁(Frame Lock) | 相容(与Quadro Sync II) |
| NVLink 互连技术 | 无 |
| 外部电源 | 8-pin PCIe |

